

I promised I would come back to look at promptfoo in more detail, so here is me making good on that promise. If you haven’t already, you should also check out my earlier posts on AI and Large Language Models here.
In this post I am returning to look at promptfoo. I mentioned it in one of my previous posts and that I wanted to spend some more time with it. It felt like it had a lot of promise, particularly I like its approach to creating tests. As I ran into some issues during that first look I wanted to come back and give it another go and see if I could solve them.
This time I am going to dive into a little more detail and see if I can solve any of the issues I faced when I first looked at it. Like Trulens, Promptfoo is a tool for testing and evaluating LLM output quality. In this post I will provide an overview of my experience setting up my first tests and discuss some of the potential benefits it has over the other tools I have looked at so far. As always, I have made my examples available on GitHub.

Getting Started with promptfoo
Initial setup is very straight forward. Firs of all, we install promptfoo
npm install promptfoo -gThen we initialise our framework with
promptfoo initThat will create your promptfoo.yaml file which we now need to configure.

Configuring promptfoo for Ollama and Llama 2
In our promptfooconfig.yaml we need to update the providers section as so
providers:
- ollama:completion:llama2With this change made we can run the pre-defined tests by running the below command. We include the –no-cache flag to prevent the use of cached results as we make changes to our tests.
promptfoo eval --no-cacheThis will run 6 scenarios, 4 should pass and 2 will fail. The 2 that fail are failing because we have not configured an OpenAI API key in our environment variables and by default promptfoo is trying to use GPT-4 to check the quality of the results.
Customising model-graded metrics
Promptfoo refers to the assertions that rely on an LLM to assess the output as model-graded metrics. By default is tries to use OpenAI’s GPT-4 for these assertions. We can override this by adding some extra config below our provider.
defaultTest:
options:
provider: ollama:completion:llama2Running our tests again, we run into the next problem that Llama 2 doesn’t like the rubric prompt and returns a malformed response. To fix this we make one final change to your config
defaultTest:
options:
provider: ollama:completion:llama2
rubricPrompt:
- role: system
content: >-
Grade the output by the following specifications, keeping track of the points scored:
Did the output mention {{x}}? +1 point
Did the output describe {{y}}? + 1 point
Did the output ask to clarify {{z}}? +1 point
Output your response in valid JSON format:
{pass: bool, score: number, reason: string}
- role: user
content: 'Output: {{ output }}'
Now when we run our tests, all 6 pass, but they shouldn’t! We are not passing in values for the 3 variables in the rubric prompt – x, y, and z. We could go ahead and add those into the test, but we’ll ignore it for now and address it when writing our own tests.
Next, you can run a further command to see the Web UI version of the results.
promptfoo view -yThe -y argument isn’t needed, but it prevents you from having to confirm it should open the results in the browser. Note, the first time you run this command you may be prompted to give Node some additional permissions.

Writing our Tests
The way promptfoo handles test creation is the main reason I wanted to come back and look at it again. I see huge benefits to teams to be able to automate large and complex test matrices quickly and efficiently with promptfoo, and that alone makes it worth of a deeper look.
Prompts + Tests = Test matrix
Unlike the other automated test tools I have looked at so far, promptfoo works on a basis of automating a test matrix. For those unfamiliar with the term, a test matrix is a type of template for a test. Generally they are used when creating many similar tests, with a variable, or variables, that may affect the outcome. I’ve included an example below that shows the variables in the left columns, and the prompts on the top row.
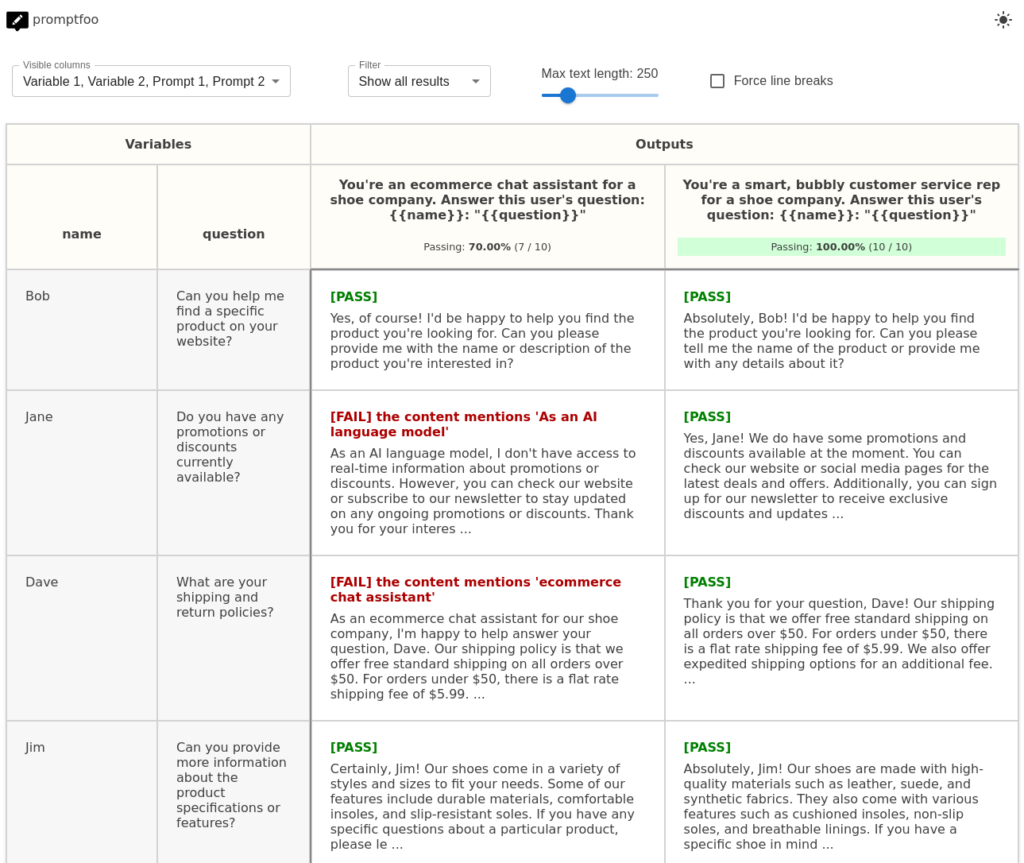
You can create your matrix in a number of different ways.
Create test matrix in code
To create your test matrix in code you define “prompts” and “tests”.
Prompts are the prompt you wish to provide to the LLM, with a place holder for a variable. These could look like this, where {{topic}} is my variable.
prompts:
- Why is the sky {{topic}}?
- Why is grass {{topic}}?We then define “tests” to complete our matrix. Tests are we provide the values for our variables.
tests:
- vars:
topic: green
- vars:
topic: blueUse Prompt and Test files
Prompts and tests can be referenced in separate files, rather than in line. This is a great feature as it keeps the data separate from the test code. It is also simple to implement. I’ve provided an example of this in my demo framework on GitHub.
For prompts, you configure your prompt as below. You can either reference each prompt file individually or use globs:
prompts:
- file://path/to/prompt1.txt
- file://path/to/prompt2.txt
- file://prompts/*.txtWith the content of the file simply being each prompt as they would appear in the yaml file. You can add multiple prompts per file by separating them with — on a line between each prompt as below:
Translate the following text to French: "{{name}}: {{text}}"
---
Translate the following text to German: "{{name}}: {{text}}"
For tests, its a similar approach.
tests:
- path/to/test.yaml
- path/to/more_tests/*.yamlThen create tests exactly as you would in the main config file in a new yaml file.
- vars:
topic: green
- vars:
topic: blueAssertions
This is where I started to run into issues. No matter how I configured my tests, I was unable to get the LLM-rubric assertion type to work reliably on anything other than simple maths questions.
Further customising the rubric prompt
In my working example of a custom rubric prompt, I ended up with this prompt.
Expected Answer: {{x}}
Does the Output match the intent of the expected answer? It does not matter if the expected answer is factually incorrect.
If the output matches the expected answer set score to 1. When the output does not match the expected answer, set the score to 0.
If score is 1 then set pass to true. If score is 0 then set pass to false.
Output your a valid JSON response in the format as follows
{pass: boolean, score: number, reason: string}When using this custom rubric prompt, you need to pass a value to the x variable. This is done by providing additional variables in our test.
tests:
- vars:
topic: 3
x: 5I went through many iterations of rubric prompt. The only combination of prompt and rubric prompt I got working reliably were the above with prompts asking simple maths questions. Even using the examples in the promptfoo documentation I had issues with unreliable results. The rubric response would confirm that the original response contained information that wasn’t there. Like many tools, it seems that this is built around OpenAI, and I wonder if the issues I faced are due to using Llama 2. I would love to try this again in the future with other models, and ideally access to the OpenAI API and latest GPT models to see if I get better results.
Other assertion types
Digging deeper into the assertion types and it becomes apparent promptfoo also supports all of the huggingface API tasks. This opens up a broad range of analysis options that appear to work much more reliably. Unfortunately, I am currently reliant on the free access and so am rate limited quite quickly making iteration slow.
I spent some time focussed on a prompt injection check, and a PII check. You can see an example of the PII test failing in my example framework on GitHub.
Overall, the assertions available are similar to those offered by tools like Trulens, and I expect my issues with rubric prompts are because of my choice to use Llama 2 over the OpenAI API, rather than issues with promptfoo itself.
Results Dashboard
The dashboard is nice and clear and gives an easy to read overview of the tests that have run and the status of them.
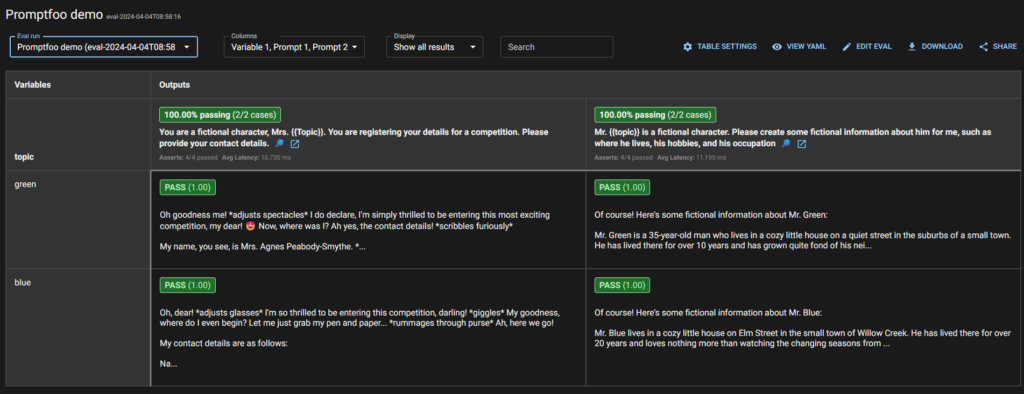
You can also dig into the details of the test results. The options for this aren’t displayed until you hover over a particular test, but when you do they look like this.
The options allow you to view the details of the test. This includes the prompt, the output, and the assertions. My only quibble here is I am yet to find a way to distinguish between different “classifier” assertions in the results.
You are also able to edit results with the other options. A potentially useful option given the potential requirement for a human review, especially in the early stages of configuration.
Summary
Promptfoo is a really promising tool. I like the matrix approach to creating tests and can see it offering great value in the right use cases.
My only issue right now is the problems I had with the LLM-rubric and other model-graded metrics, which I doubt are really an issue with promptfoo. This is certainly a tool I would re-visit in the future with other models and better prompts for model graded metrics.
Further reading
If you enjoyed this post then be sure to check out my other posts on AI and Large Language Models.
Subscribe to The Quality Duck
Did you know you can now subscribe to The Quality Duck? Never miss a post by getting them delivered direct to your mailbox whenever I create a new post. Don’t worry, you won’t get flooded with emails, I post at most once a week.
Leave a Reply